

来源:https://zhuanlan.zhihu.com/p/25532538
超分辨率技术(Super-Resolution)是指从观测到的低分辨率图像重建出相应的高分辨率图像,在监控设备、卫星图像和医学影像等领域都有重要的应用价值。SR可分为两类:从多张低分辨率图像重建出高分辨率图像和从单张低分辨率图像重建出高分辨率图像。基于深度学习的SR,主要是基于单张低分辨率的重建方法,即Single Image Super-Resolution (SISR)。
SISR是一个逆问题,对于一个低分辨率图像,可能存在许多不同的高分辨率图像与之对应,因此通常在求解高分辨率图像时会加一个先验信息进行规范化约束。在传统的方法中,这个先验信息可以通过若干成对出现的低-高分辨率图像的实例中学到。而基于深度学习的SR通过神经网络直接学习分辨率图像到高分辨率图像的端到端的映射函数。
本文介绍几个较新的基于深度学习的SR方法,包括SRCNN,DRCN, ESPCN,VESPCN和SRGAN等。
1 SRCNN
Super-Resolution Convolutional Neural Network (SRCNN, PAMI 2016, 代码)是较早地提出的做SR的卷积神经网络。该网络结构十分简单,仅仅用了三个卷积层。
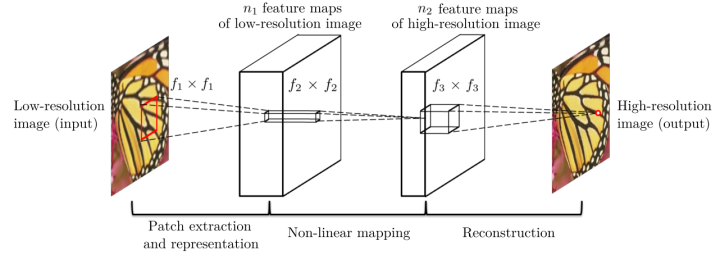 该方法对于一个低分辨率图像,先使用双三次(bicubic)插值将其放大到目标大小,再通过三层卷积网络做非线性映射,得到的结果作为高分辨率图像输出。作者将三层卷积的结构解释成与传统SR方法对应的三个步骤:图像块的提取和特征表示,特征非线性映射和最终的重建。
该方法对于一个低分辨率图像,先使用双三次(bicubic)插值将其放大到目标大小,再通过三层卷积网络做非线性映射,得到的结果作为高分辨率图像输出。作者将三层卷积的结构解释成与传统SR方法对应的三个步骤:图像块的提取和特征表示,特征非线性映射和最终的重建。
三个卷积层使用的卷积核的大小分为为9x9, 1x1和5x5,前两个的输出特征个数分别为64和32. 该文章分别用Timofte数据集(包含91幅图像)和ImageNet大数据集进行训练。相比于双三次插值和传统的稀疏编码方法,SRCNN得到的高分辨率图像更加清晰,下图是一个放大倍数为3的例子。
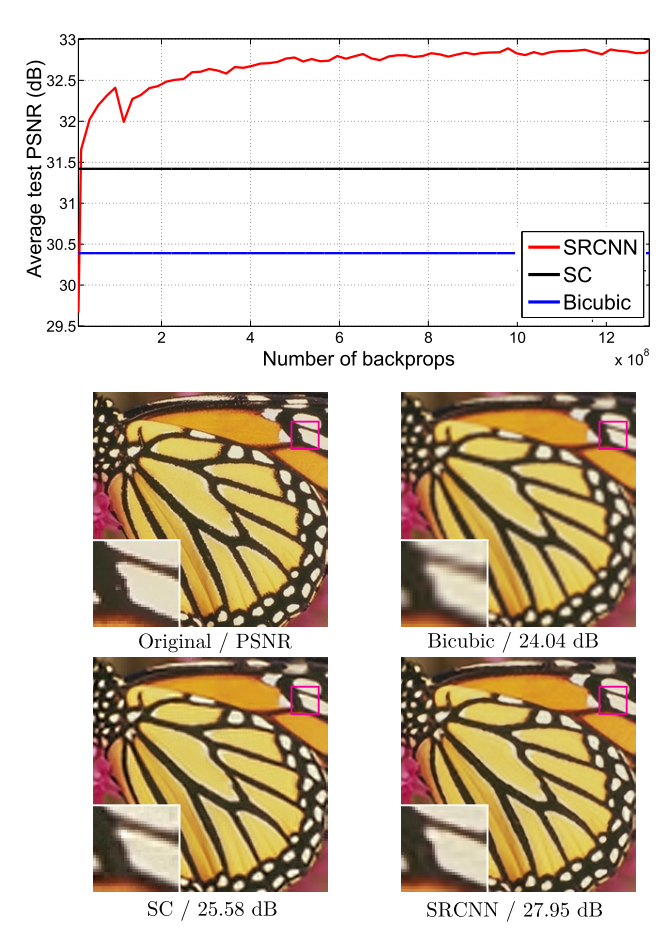 对SR的质量进行定量评价常用的两个指标是PSNR(Peak Signal-to-Noise Ratio)和SSIM(Structure Similarity Index)。这两个值越高代表重建结果的像素值和金标准越接近,下图表明,在不同的放大倍数下,SRCNN都取得比传统方法好的效果。
对SR的质量进行定量评价常用的两个指标是PSNR(Peak Signal-to-Noise Ratio)和SSIM(Structure Similarity Index)。这两个值越高代表重建结果的像素值和金标准越接近,下图表明,在不同的放大倍数下,SRCNN都取得比传统方法好的效果。 2 DRCN
2 DRCN
SRCNN的层数较少,同时感受野也较小(13x13)。DRCN (Deeply-Recursive Convolutional Network for Image Super-Resolution, CVPR 2016, 代码)提出使用更多的卷积层增加网络感受野(41x41),同时为了避免过多网络参数,该文章提出使用递归神经网络(RNN)。网络的基本结构如下:
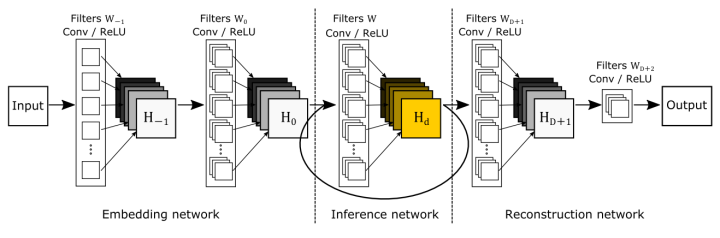 与SRCNN类似,该网络分为三个模块,第一个是Embedding network,相当于特征提取,第二个是Inference network, 相当于特征的非线性变换,第三个是Reconstruction network,即从特征图像得到最后的重建结果。其中的Inference network是一个递归网络,即数据循环地通过该层多次。将这个循环进行展开,就等效于使用同一组参数的多个串联的卷积层,如下图所示:
与SRCNN类似,该网络分为三个模块,第一个是Embedding network,相当于特征提取,第二个是Inference network, 相当于特征的非线性变换,第三个是Reconstruction network,即从特征图像得到最后的重建结果。其中的Inference network是一个递归网络,即数据循环地通过该层多次。将这个循环进行展开,就等效于使用同一组参数的多个串联的卷积层,如下图所示:
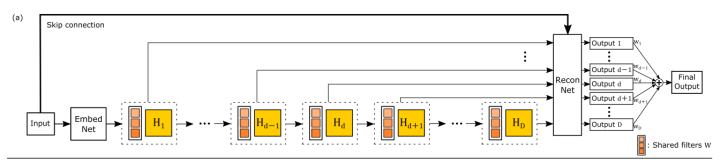

在SRCNN和DRCN中,低分辨率图像都是先通过上采样插值得到与高分辨率图像同样的大小,再作为网络输入,意味着卷积操作在较高的分辨率上进行,相比于在低分辨率的图像上计算卷积,会降低效率。 ESPCN(Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network,CVPR 2016, 代码)提出一种在低分辨率图像上直接计算卷积得到高分辨率图像的高效率方法。
 ESPCN的核心概念是亚像素卷积层(sub-pixel convolutional layer)。如上图所示,网络的输入是原始低分辨率图像,通过两个卷积层以后,得到的特征图像大小与输入图像一样,但是特征通道为
ESPCN的核心概念是亚像素卷积层(sub-pixel convolutional layer)。如上图所示,网络的输入是原始低分辨率图像,通过两个卷积层以后,得到的特征图像大小与输入图像一样,但是特征通道为
重建效果上,用PSNR指标看来ESPCN比SRCNN要好一些。对于1080HD的视频图像,做放大四倍的高分辨率重建,SRCNN需要0.434s而ESPCN只需要0.029s。
4 VESPCN
在视频图像的SR问题中,相邻几帧具有很强的关联性,上述几种方法都只在单幅图像上进行处理,而VESPCN( Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation, arxiv 2016)提出使用视频中的时间序列图像进行高分辨率重建,并且能达到实时处理的效率要求。其方法示意图如下,主要包括三个方面:
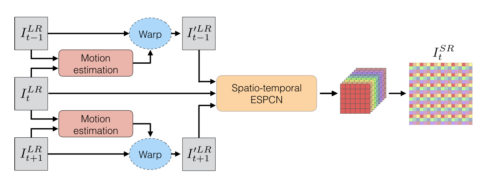 一是纠正相邻帧的位移偏差,即先通过Motion estimation估计出位移,然后利用位移参数对相邻帧进行空间变换,将二者对齐。二是把对齐后的相邻若干帧叠放在一起,当做一个三维数据,在低分辨率的三维数据上使用三维卷积,得到的结果大小为[图片] 由于SR重建和相邻帧之间的位移估计都通过神经网路来实现,它们可以融合在一起进行端到端的联合训练。为此,VESPCN使用的损失函数如下:
一是纠正相邻帧的位移偏差,即先通过Motion estimation估计出位移,然后利用位移参数对相邻帧进行空间变换,将二者对齐。二是把对齐后的相邻若干帧叠放在一起,当做一个三维数据,在低分辨率的三维数据上使用三维卷积,得到的结果大小为[图片] 由于SR重建和相邻帧之间的位移估计都通过神经网路来实现,它们可以融合在一起进行端到端的联合训练。为此,VESPCN使用的损失函数如下:
[图片] 第一项是衡量重建结果和金标准之间的差异,第二项是衡量相邻输入帧在空间对齐后的差异,第三项是平滑化空间位移场。下图展示了使用Motion Compensation 后,相邻帧之间对得很整齐,它们的差值图像几乎为0.
[图片] 从下图可以看出,使用了Motion Compensation,重建出的高分辨率视频图像更加清晰。[图片]5 SRGAN
SRGAN (Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, arxiv, 21 Nov, 2016)将生成式对抗网络(GAN)用于SR问题。其出发点是传统的方法一般处理的是较小的放大倍数,当图像的放大倍数在4以上时,很容易使得到的结果显得过于平滑,而缺少一些细节上的真实感。因此SRGAN使用GAN来生成图像中的细节。
传统的方法使用的代价函数一般是最小均方差(MSE),即
[图片]
该代价函数使重建结果有较高的信噪比,但是缺少了高频信息,出现过度平滑的纹理。SRGAN认为,应当使重建的高分辨率图像与真实的高分辨率图像无论是低层次的像素值上,还是高层次的抽象特征上,和整体概念和风格上,都应当接近。整体概念和风格如何来评估呢?可以使用一个判别器,判断一副高分辨率图像是由算法生成的还是真实的。如果一个判别器无法区分出来,那么由算法生成的图像就达到了以假乱真的效果。
因此,该文章将代价函数改进为
[图片] 第一部分是基于内容的代价函数,第二部分是基于对抗学习的代价函数。基于内容的代价函数除了上述像素空间的最小均方差以外,又包含了一个基于特征空间的最小均方差,该特征是利用VGG网络提取的图像高层次特征:[图片] 对抗学习的代价函数是基于判别器输出的概率:[图片] 其中[图片]
该方法的实验结果如下[图片] 从定量评价结果上来看,PSNR和SSIM这两个指标评价的是重建结果和金标准在像素值空间的差异。SRGAN得到的评价值不是最高。但是对于MOS(mean opinion score)的评价显示,SRGAN生成的高分辨率图像看起来更真实。[图片]
请登录后评论~